1. LDM 之前的“前夜”—— 传统模型有什么问题?为什么会有问题?
在 LDM 出现之前,图像生成领域主要由 GAN、VAE 以及早期的像素级扩散模型(如 DDPM)占据主导。但它们各自面临着难以逾越的瓶颈:
1.1 GAN 与 VAE 的两难困境
- GAN(生成对抗网络): 能够生成极其锐利的图像,但由于缺乏明确的似然函数,训练过程极度不稳定,且容易陷入“模式崩溃”(Mode Collapse),无法覆盖完整的数据分布。
- VAE(变分自编码器): 拥有优美的数学概率基础和稳定的训练过程。为什么 VAE 生成的图像总是很模糊? 因为传统 VAE 为了强迫潜空间服从简单的标准高斯先验,施加了极其强烈的 KL 散度惩罚,这导致重构误差与先验匹配产生严重冲突,模型只能输出平滑、缺乏高频细节的模糊图像。
1.2 像素级扩散模型(Pixel-DMs)的“算力黑洞”
DDPM 成功解决了 GAN 的不稳定和 VAE 的模糊问题,但它带来了新的问题:极其缓慢的训练与推理速度。
为什么像素级扩散模型会有这个问题?
- 在像素空间中挣扎: 数字图像中包含了大量人类视觉根本无法察觉的高频细节(Imperceptible details)。
- 资源的巨大浪费: 传统的扩散模型直接在极高维度的 RGB 像素空间中进行马尔可夫加噪和去噪。虽然模型可以通过优化损失函数来抑制这些无意义的细节,但神经网络的每一次前向传播、梯度的每一次反向计算,都必须在数以百万计的像素上进行。
- 结果: 优化一个强大的像素级扩散模型通常需要消耗数百个 GPU days,且由于去噪过程的序列化特性,生成一张图像的成本极高。
2. LDM 的核心哲学 —— 将“感知压缩”与“语义生成”彻底解耦
为了解决上述问题,LDM(Latent Diffusion Models)的作者提出了一个极其深刻的洞察:图像的生成过程可以被分为两个截然不同的阶段。
- 感知压缩(Perceptual Compression): 剔除图像中对人类视觉无意义的高频细节,将高维像素压缩为低维特征。
- 语义压缩与生成(Semantic Compression): 学习图像中物体的高层语义、概念组合及其全局概率分布。
LDM 是如何解决传统模型问题的?
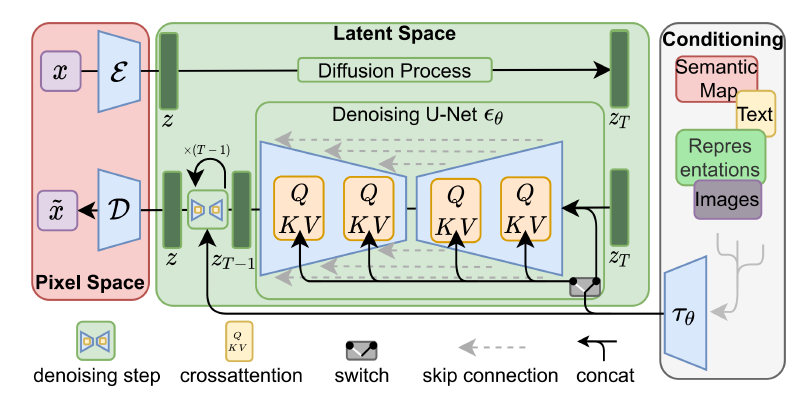
LDM 放弃了在像素空间直接训练扩散模型。它首先训练一个强大的自编码器(Autoencoder),将图像压缩到一个低维但信息高度浓缩的潜空间(Latent Space)中。然后,它在这个低维的潜空间里训练扩散模型。
为什么 LDM 能够解决问题?
因为低维潜空间屏蔽了高频噪声,扩散模型可以 100% 专注于学习图像的语义结构;同时,维度的呈几何级数降低,使得训练和推理的计算成本呈指数级下降,完美实现了“降维打击”。
3. LDM 的第一阶段 —— 极致的感知压缩(自编码器)
LDM 的第一步,是独立训练一个感知压缩自编码器,包含编码器 $E$ 和解码器 $D$。
3.1 网络架构与下采样
给定一张 RGB 图像 $x \in \mathbb{R}^{H \times W \times 3}$,编码器 $E$ 将其映射为潜变量表示 $z = E(x)$,解码器 $D$ 再将其重构为 $\tilde{x} = D(z)$。 这里潜变量 $z \in \mathbb{R}^{h \times w \times c}$ 保留了二维的网格结构。相比于原图,它在空间维度上下采样了 $f$ 倍,即 $f = H/h = W/w$。作者实验了 $f \in \{1, 2, 4, 8, 16, 32\}$,最终发现 $f=4$ 和 $f=8$ 能够达到效率与质量的最佳平衡。过小的 $f$ 依然计算缓慢,而过大的 $f$(如 32)会导致信息丢失,限制了最终的生成质量。
3.2 避免方差爆炸:微小正则化的精妙设计
为什么这里不能直接用普通的自编码器(AE)?
如果不对潜空间施加任何约束,AE 会通过“尺度作弊”让潜空间的方差任意膨胀。扩散模型对数据的方差极为敏感,方差爆炸的潜空间会彻底摧毁扩散过程的信噪比。
为了解决这个问题,LDM 引入了两种微度的正则化方案:
- KL-reg: 对潜变量施加一个权重极其微小(如 $10^{-6}$)的 KL 惩罚,使其轻微向标准正态分布靠拢。
- VQ-reg: 在解码器内部引入向量量化(Vector Quantization)层,利用离散密码本限制数值范围。
为什么这种“微弱惩罚”没有导致传统 VAE 的模糊问题?
因为 LDM 的自编码器结合了感知损失(Perceptual Loss) 和基于 Patch 的对抗损失(PatchGAN),这强迫模型在局部纹理上保持极高的逼真度。
3.3 第一阶段目标函数
自编码器的完整优化目标是一个最小-最大博弈问题(原始论文附录公式 25):
$$L_{Autoencoder} = \min_{E,D} \max_{\psi} \left( L_{rec}(x, D(E(x))) - L_{adv}(D(E(x))) + \log D_\psi(x) + L_{reg}(x; E, D) \right)$$- $L_{rec}$:结合了感知损失的重构误差,保证语义还原。
- $L_{adv}, \log D_\psi$:对抗损失,对抗模糊,保证细节锐利。
- $L_{reg}$:极微小的 KL 或 VQ 正则化,锁住潜空间的尺度边界。
4. LDM 的第二阶段 —— 潜空间中的扩散魔法
在自编码器训练完毕并冻结权重后,LDM 开始在低维潜空间 $z$ 中训练扩散模型。
4.1 尺度缩放(Rescaling)的必要性
即便有微弱的 KL 正则化,提取出的 $z$ 的方差依然不为 1。为了匹配扩散模型对信噪比的严苛要求,LDM 会估算出潜变量的逐分量标准差 $\hat{\sigma}$,并在前向加噪前强制进行缩放:$z \leftarrow z / \hat{\sigma}$。
4.2 潜空间的去噪目标函数
在像素空间的传统扩散模型,其简化目标函数为:
$$L_{DM} = \mathbb{E}_{x,\epsilon\sim\mathcal{N}(0,1),t} \left[ ||\epsilon - \epsilon_\theta(x_t, t)||_2^2 \right]$$而 LDM 将这一过程无缝迁移到了潜空间。它采用带有二维空间归纳偏置的 U-Net($\epsilon_\theta$)作为骨干网络。由于脱离了高频像素的干扰,模型现在可以专注于最重要的“语义位(Semantic bits)”。无条件 LDM 的目标函数被改写为(原始论文公式 2):
$$L_{LDM} := \mathbb{E}_{\mathcal{E}(x),\epsilon\sim\mathcal{N}(0,1),t} \left[ ||\epsilon - \epsilon_\theta(z_t, t)||_2^2 \right]$$4.3 解答核心疑问:为什么 LDM 采样时不会像 AE 那样生成无意义的乱码?
由于 LDM 的第一阶段为了保留细节,几乎放任潜空间变成了充满“空洞”的不规则地形。如果你像传统 VAE 那样直接从 $\mathcal{N}(0,I)$ 盲目抽样并解码,注定会得到乱码。
但 LDM 并不是在盲目抽样。
在生成阶段,起点确实是纯噪声 $z_T \sim \mathcal{N}(0, 1)$。但接下来,极其强大的扩散模型(U-Net)接管了导航任务。在从 $t=T$ 到 $t=0$ 的多步去噪过程中,扩散模型凭借学习到的复杂流形梯度(Score Matching),精准地引导这个随机噪声避开所有的“无意义空洞”,一步步被拉扯回蕴含真实图像语义的合法区间 $z_0$。最后将这个合法的 $z_0$ 送入解码器 $D$,就能瞬间显影为极其清晰的高分辨率图像。
5. LDM 的“杀手锏” —— 交叉注意力(Cross-Attention)条件机制
LDM 之所以能成为通用生成框架(尤其是文本到图像生成的霸主),归功于它对 U-Net 骨干网络的巧妙改造:引入了交叉注意力机制。这使得模型不仅能生成图像,还能精准听懂各种模态的条件指令 $y$(如文本、布局图)。
5.1 领域特定编码器(Domain Specific Encoder)
对于任意模态的输入 $y$,LDM 引入了一个特定的编码器 $\tau_\theta$(例如,处理文本时,$\tau_\theta$ 可以是未掩码的 Transformer)。它将条件 $y$ 映射为中间表示矩阵 $\tau_\theta(y) \in \mathbb{R}^{M \times d_\tau}$。
5.2 交叉注意力的工作原理
在 U-Net 的各个网络层级中,潜变量图像的中间特征 $\phi_i(z_t) \in \mathbb{R}^{N \times d_\epsilon^i}$ 会与条件矩阵进行深度融合。
模型引入了可学习的投影矩阵 $W_Q^{(i)}, W_K^{(i)}, W_V^{(i)}$。
角色分配如下:
- Query (Q) 来自图像: $Q = W_Q^{(i)} \cdot \phi_i(z_t)$。(图像特征在询问:我这里该画什么?)
- Key (K) 和 Value (V) 来自条件: $K = W_K^{(i)} \cdot \tau_\theta(y)$, $V = W_V^{(i)} \cdot \tau_\theta(y)$。(文本指令在提供语义答复。)
注意力计算公式为:
$$Attention(Q,K,V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d}}\right) \cdot V$$5.3 条件 LDM 目标函数
在引入交叉注意力后,领域编码器 $\tau_\theta$ 和 U-Net 主干网络 $\epsilon_\theta$ 通过以下目标函数进行联合优化(原始论文公式 3):
$$L_{LDM} := \mathbb{E}_{\mathcal{E}(x), y, \epsilon\sim\mathcal{N}(0,1), t} \left[ ||\epsilon - \epsilon_\theta(z_t, t, \tau_\theta(y))||_2^2 \right]$$在这个过程中,文本编码器不仅在学习语言,更是在学习“如何生成对扩散模型去噪最有利的条件向量”。
6. 结语:LDM 的深远意义
《High-Resolution Image Synthesis with Latent Diffusion Models》这篇论文,其伟大之处不在于提出了全新的数学概率模型,而在于它极其精妙的工程直觉与架构解耦。
它敏锐地察觉到“压缩”和“生成”是两件截然不同的事情。通过将感知压缩交给自编码器,将语义生成交给潜空间扩散模型,辅以灵活的交叉注意力机制,LDM(Latent Diffusion Models)不仅在训练效率和采样速度上实现了质的飞跃,更开启了多模态高分辨率图像生成的全新纪元。这正是我们今天能够轻松在消费级显卡上运行 Stable Diffusion 的基石。